Table of Contents
Exploring Properties of Intralingual and Interlingual Association Measures Visually
Our work relies on a multingual corpus that we automatically annotate on several levels (tagging, lemmatization, dependency parsing) and align on a sentence and word level (see Figure 1). We calculate intralingual and interlingual association measures as described here, which helps us identifying phrasemes. Phrasemes are characterized by being more than the sum of their lexical units. Exploiting this property, we can derive lists of support verb constructions such as the ones shown in Table 1 by combining intralingual and interlingual association measures.
Here, we provide a web interface to explore the properties of different association measures: https://pub.cl.uzh.ch/projects/sparcling/visual_association_measures/
We describe our interface in Graën, Johannes; Bless, Christof (2017). Exploring Properties of Intralingual and Interlingual Association Measures Visually.
Furthermore, we publish the visualisation library we implemented for illustrating annotated and aligned sentences such as shown in Figure 1: https://gitlab.cl.uzh.ch/sparcling/SentStructure.js A feature demonstration of SentStructure.js is available at https://pub.cl.uzh.ch/projects/sparcling/SentStructureDemo/.
Figure 1
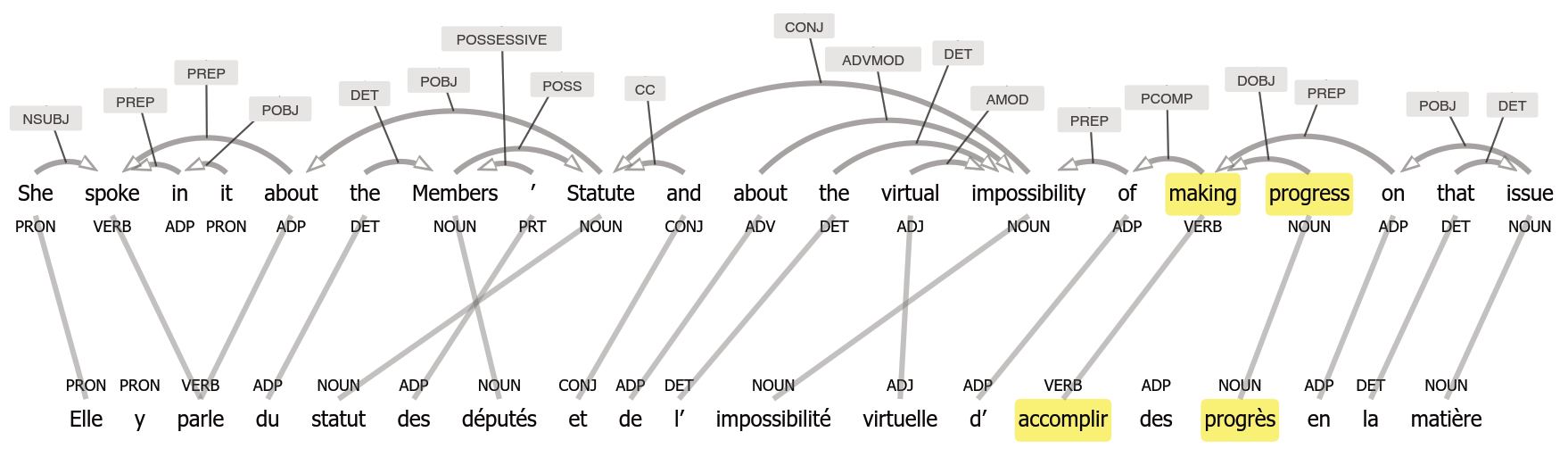 Sample sentence with tagging, dependency parsing and word alignment. The hightlighted tokens belong to a support verb candidate in English and the respective aligned tokens in French.
Sample sentence with tagging, dependency parsing and word alignment. The hightlighted tokens belong to a support verb candidate in English and the respective aligned tokens in French.
Table 1

Support verb constructions identified by employing intralingual and interlinguals association measures (source).