public:users:graen:jointsentalign
Table of Contents

Joint Approaches for Sentence Alignment on Multiparallel Texts
Johannes Graën
2016-11-29
Overview
- Sentence Alignment on Multiparallel Texts
- Approaches
- Agreement of Bilingual Alignments
- Sampling in Discrete Vector Space
- Agglomerative Hierarchical Clustering
- Outlook
- Evaluation Metrics
- Hierarchical Clustering for Word Alignment
Sentence Alignment on Multiparallel Texts
- Like sentence alignment of two languages.
- There may be alignments that only exists on a subset of languages.
- This leads to hierarchical alignments.
- Alignments can be partially correct.
- Evaluation requires more than counting right and wrong alignments.
Example
| de | Es geht nicht um die Großzügigkeit des Präsidenten, es geht um die Zeit, die Sie sich selbst genehmigen; [1+3] ich habe Ihnen angezeigt, wann die Minute abgelaufen war. [2+3] |
| en | Mr Izquierdo Collado, it is not a question of the President’s generosity. [3] It is a question of the time you allow yourself, because I informed you when your minute was up. [3] |
| fr | Monsieur Izquierdo, il ne s’agit pas de la générosité du président, il s’agit du temps que vous vous attribuez. [1+3] Je vous ai fait signe quand vous avez atteint la minute. [2+3] |
Agreement of Bilingual Alignments
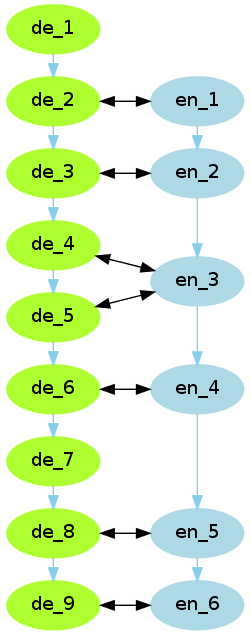
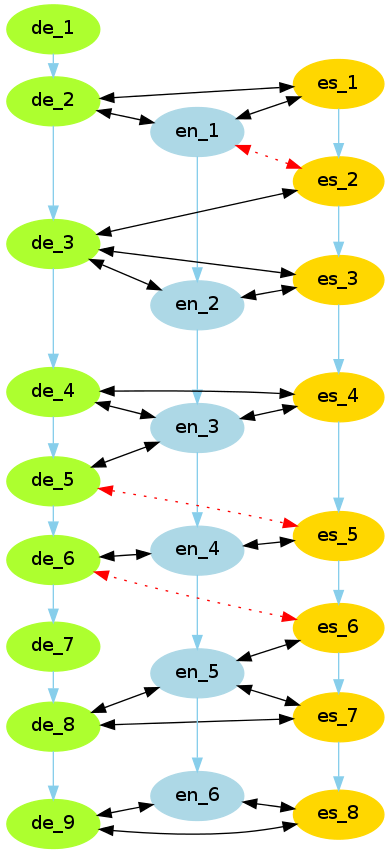
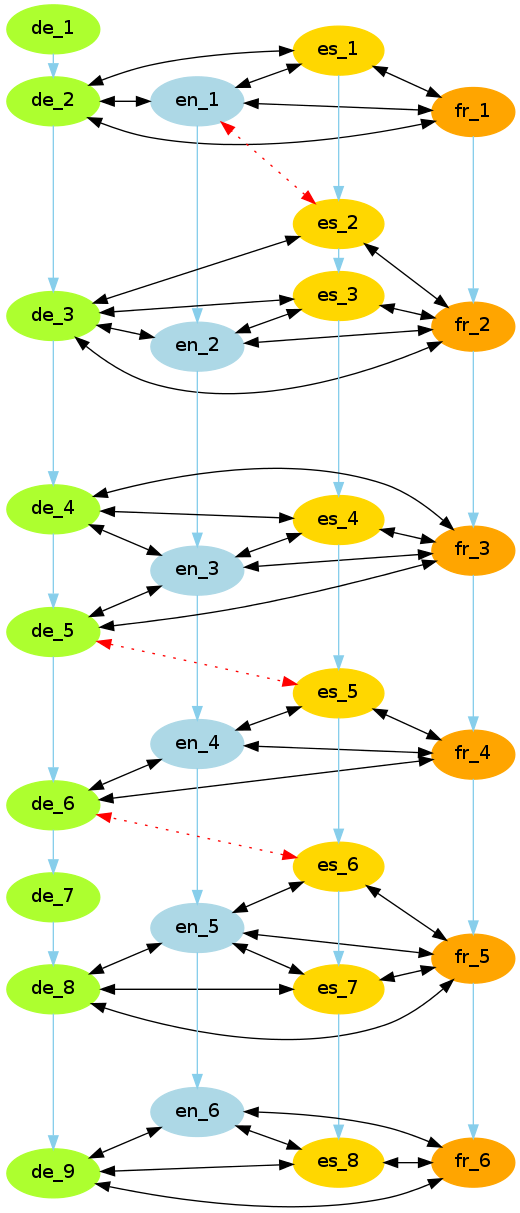
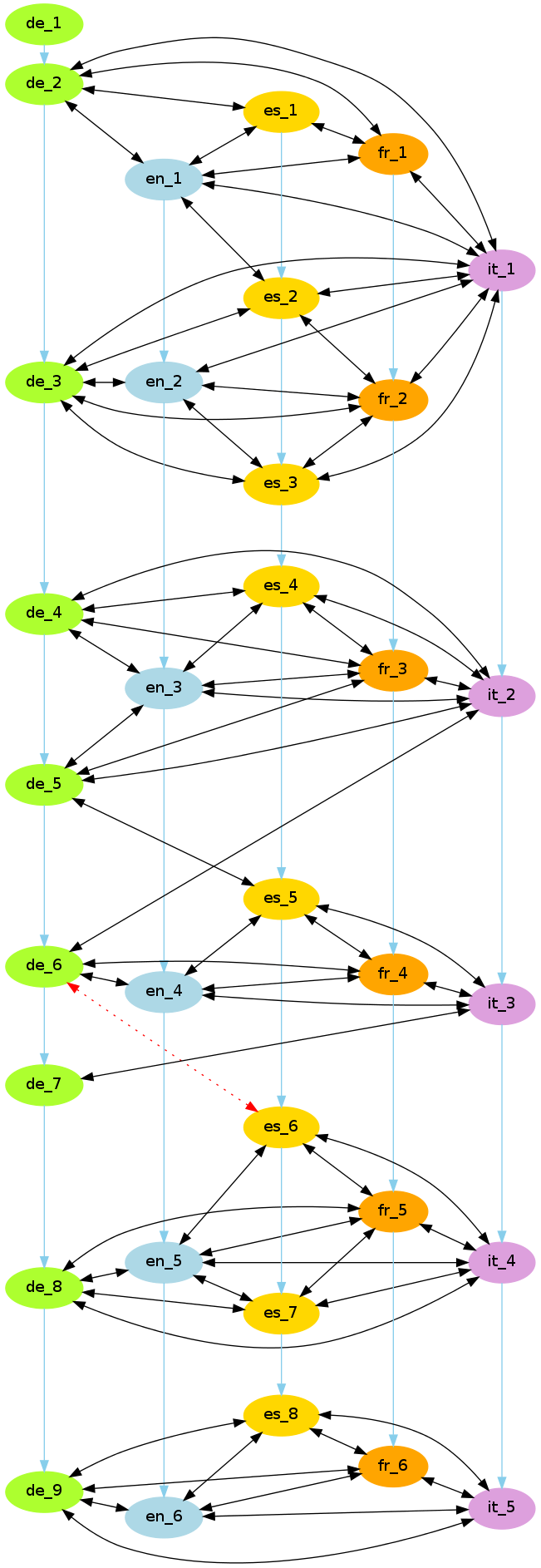
- Perform sentence alignment on all language pairs.
- Derive correct alignments by “voting”.
- Hypothesis: The majority of pairwise alignments is correct in most cases, i.e. any alignment error is due to the properties of its particular language pair.
Approach
- Perform pairwise alignments with hunalign.
- Join all these alignments in a graph.
- Calculate “connectedness” by counting supporting languages for each edge.
- How many languages align with both sentences of a particular language pair?
- Continue deleting the least supported edge until small consistent clusters emerge.
- An alignment hierarchy can be obtained by reversing the deletion process.
Two Languages
Three Languages
Four Languages
Five Languages
Hierarchical Alignments
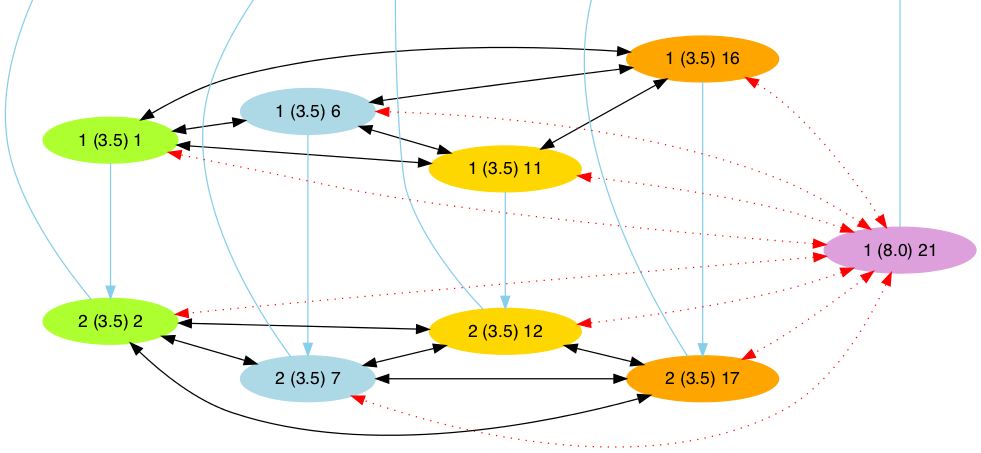
Problems/Limitations
- Short sentences in 1:n pairs do not align in any language.
- … and we are merely removing (wrong) alignments.
- Decisions not straightforward if more than one pair disagrees.
- hunalign's alignment score does not help taking the right decision.
- Dictionaries for hunalign only allow binary entries.
Sampling in Discrete Vector Space
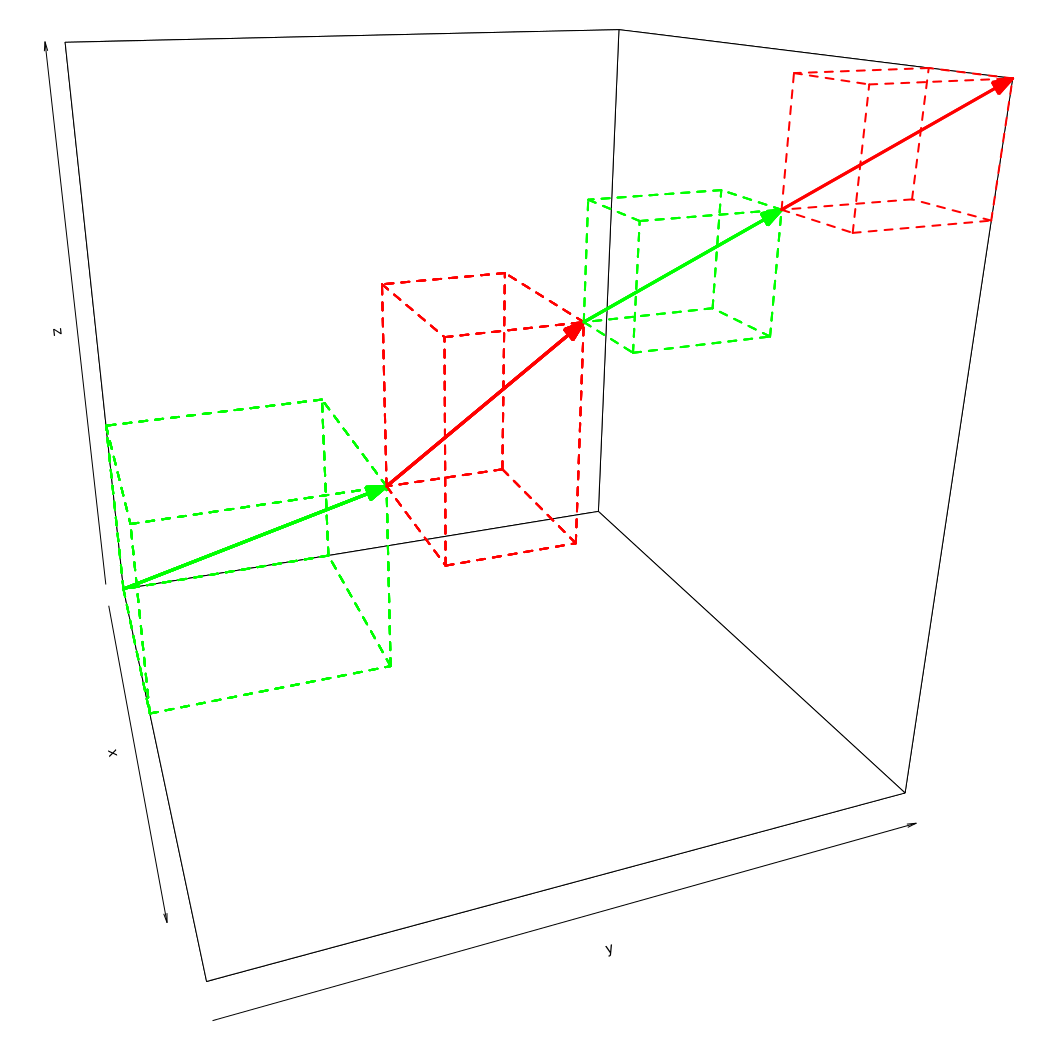
- Discrete vector space spanned by languages as dimensions.
- Alignments are pairs of location and direction vectors with all positive components.
- E.g. $\left((1,2)^T,(2,1)^T\right)$ defines the alignment of the second and third sentence of the first language with the third sentence of the second language.
- The location vector of the nth alignment equals the sum of the direction vector 1..n-1.
- Alignment is obtained by simulated annealing.
Visual Representation
Approach
- Set initial aligment to a sequence of vectors approximating a diagonal line.
- Calculate local (pairwise) and global alignment scores (and keep results in memory).
- Find and evaluate all applicable sampling operations.
- Sample by selecting one of those operations – according to their respective evaluation scores.
- Lower temperature, i.e. probability of picking an operation that leads to a worse sample.
- Repeat from (3) until temperature reaches zero-point.
Sampling Operations
- Changing two consecutive vectors $\vec{x}$ and $\vec{y}$ such that $\vec{x}^\prime + \vec{y}^\prime = \vec{x} + \vec{y}$.
- Replace two consecutive vectors $\vec{x}$ and $\vec{y}$ by vector $\vec{z}$ such that $\vec{z} = \vec{x} + \vec{y}$.
- Split a vector $\vec{z}$ into vectors $\vec{x}$ and $\vec{y}$ such that $\vec{x} + \vec{y} = \vec{z}$.
Problems/Limitations
- The sampling often does not converge.
- For higher dimensions (more languages), sampling did not inlcude the correct (gold) alignment.
- Finding and evaluation all applicable operations is expensive, even if scores are only calculated on language pairs.
Agglomerative Hierarchical Clustering
- Collect evidence from different sources/heuristics in a graph.
- Perform agglomerative clustering such that
- a cluster cannot take more than one sentence of each language.
- crossing clusters are prohibited.
- Join incomplete clusters (not every language covered) with complete clusters.
Approach
- Calculate scores for each a) language pair, b) source and c) sentence pair.
- Map the (normal) distribution of each source's scores to one with $\mu = 1$ and $\sigma = 1$ and
- multiply the values with a source-specific weight between 0 and 1.
- Sum up these score-specific values to set the link weight between each two sentences.
- Calculate the supported link weight based on the weight of a particular link and the link weights of all “triangles” with other languages.
- Use those weights for clustering.
Approach (Clustering)
- Perform first agglomerative clustering such that
- a cluster cannot take more than one sentence of each language.
- crossing clusters are prohibited.
- Let all remaining sentences be the only member of their own cluster.
- Perform secondary agglomerative clustering for incomplete clusters such that
- crossing clusters are prohibited.
Sources for Pairwise Scores
- Corresponding discourse markers
- Phrase table matches
- Identical punctuation
- Relative cumulative length
- Identical numbers
- Identical acronyms
Demo
Evaluation Metrics
- Gold standard for multiparallel hierarchical sentence alignment (Tool)
- Evaluation of bilingual sentence aligners:
- Minimal bilingual alignments can be extracted from gold standard for each language pair
- Evaluation of multiparallel clustering approach:
- Minimal bilingual alignments of both data sets
- Average and standard deviation of those bilingual scores per language
- Distribution of errors by average sentence count
Hierarchical Clustering for Word Alignment
- Almost the same approach
- Preliminary results promising
- Evaluation against gold standard (Tool)
EOP
public/users/graen/jointsentalign.txt · Last modified: 2023-09-15 20:33 by 127.0.0.1