This is an old revision of the document!
Table of Contents
Cutter – a Universal Multilingual Tokenizer
Cutter is a rule-based tokenizer that is easily adaptable to other languages and text types. It currently supports Catalan, Dutch, English, French, German, Italian, Portuguese, Romansh, Spanish and Swedish, but can also be used without any language-specific rules.
History
- end of 2015 – concept and first development version (PHP)
- April 2016 – first release
- until May 2017 – continued development for up to 17 languages
- from January 2018 – reimplementation in Python
- June 2018 – released as Python module
- November 2018 – released as PyPI package
Demos
The current version is always available at https://pub.cl.uzh.ch/projects/sparcling/cutter/current/.
- version 1.0 (Apr. 2016)
- version 1.2 (Jul. 2016)
- version 1.4 (Feb. 2017)
- version 1.6 (May 2017)
- version 2.0 (June 2018)
- version 2.1 (August 2018)
- version 2.2 (September 2018)
- version 2.3 (November 2018)
- version 2.4 (January 2019)
- version 2.5 (June 2019)
Source
- graen/cutter (version 1.x – PHP)
- graen/cutter-ng and https://github.com/j0hannes/cutter-ng (version 2.x – Python3)
PyPI package
We provide the newer Python version of Cutter as a PyPI package: https://pypi.org/project/cutter-ng/
It can simply be used with its pre-defined profiles like this:
import Cutter cutter = Cutter.Cutter(profile='fr') text = "On nous dit qu’aujourd’hui c’est le cas, encore faudra-t-il l’évaluer." for token in cutter.cut(text): print(token)
Which will return the following tuples:
| Token | Tag | Tree | Start | End |
|---|---|---|---|---|
| On | frRtkA | 3 | 0 | 2 |
| nous | frRtkA | 4 | 3 | 7 |
| dit | frRtkA | 5 | 8 | 11 |
| qu’ | frXel | 2 | 12 | 15 |
| aujourd’hui | frQlx | 1 | 15 | 26 |
| c’ | frXel | 2 | 27 | 29 |
| est | frRtkA | 6 | 29 | 32 |
| le | frRtkA | 7 | 33 | 35 |
| cas | frRtkB | 8 | 36 | 39 |
| , | +punct | 5 | 39 | 40 |
| encore | frRtkA | 6 | 41 | 47 |
| faudra | frRtkB | 7 | 48 | 54 |
| -t-il | frXpr1 | 4 | 54 | 59 |
| l’ | frXel | 3 | 60 | 62 |
| évaluer | frRtkB | 5 | 62 | 69 |
| . | +dot | 4 | 69 | 70 |
| +EOS5 | 4 | 70 | 70 |
By means of the third column, the tokenization tree can be reconstructed:
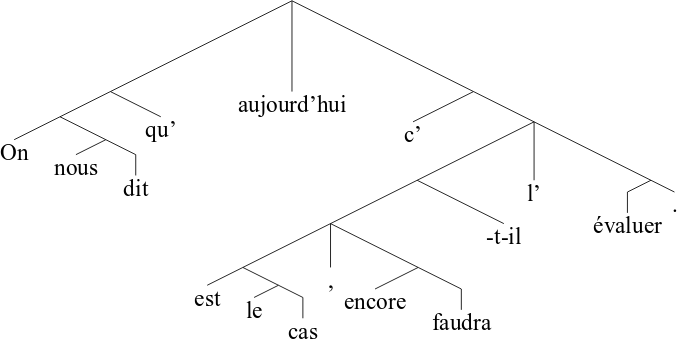
Web service
We also provide a web service for tokenization using one of the pre-defined profiles:
echo "text=On nous dit qu’aujourd’hui c’est le cas, encore faudra-t-il l’évaluer." \ | curl --data @- https://pub.cl.uzh.ch/service/cutter-ng/current/fr/ \ | jq
This call returns a JSON object comprising a list of tokens and their respective tags:
[
{
"tag": "frRtkA",
"tok": "On"
},
{
"tag": "frRtkA",
"tok": "nous"
},
{
"tag": "frRtkA",
"tok": "dit"
},
{
"tag": "frXel",
"tok": "qu’"
},
{
"tag": "frQlx",
"tok": "aujourd’hui"
},
{
"tag": "frXel",
"tok": "c’"
},
{
"tag": "frRtkA",
"tok": "est"
},
{
"tag": "frRtkA",
"tok": "le"
},
{
"tag": "frRtkB",
"tok": "cas"
},
{
"tag": "+punct",
"tok": ","
},
{
"tag": "frRtkA",
"tok": "encore"
},
{
"tag": "frRtkB",
"tok": "faudra"
},
{
"tag": "frXpr1",
"tok": "-t-il"
},
{
"tag": "frXel",
"tok": "l’"
},
{
"tag": "frRtkB",
"tok": "évaluer"
},
{
"tag": "+dot",
"tok": "."
},
{
"tag": "+EOS5",
"tok": ""
}
]
Contributors
- Johannes Graën
- Martin Volk
- Mara Bertamini
- Chantal Amrhein
- Phillip Ströbel
- Anne Göhring
- Natalia Korchagina
- Simon Clematide
- Daniel Wüest
- Alex Flückiger
Citation
See also https://doi.org/10.5167/uzh-157243.
- cutter.bib
@inproceedings{GraenBertaminiVolk2018, number = {2226}, month = {June}, author = {Johannes Gra{\"e}n and Mara Bertamini and Martin Volk}, series = {CEUR Workshop Proceedings}, booktitle = {Swiss Text Analytics Conference}, editor = {Mark Cieliebak and Don Tuggener and Fernando Benites}, title = {Cutter -- a Universal Multilingual Tokenizer}, publisher = {CEUR-WS}, year = {2018}, pages = {75--81}, url = {https://doi.org/10.5167/uzh-157243}, issn = {1613-0073}, }