Exploiting Alignment in
Multiparallel Corpora for
Applications in Linguistics
and Language Learning
Johannes Graën
2018-03-19
Thesis Overview
- Corpus Annotation
- Tokenization
- PoS Tagging & Lemmatization
- Dependency Parsing
- Database Corpus
- Alignment Methods
- Text Alignment
- Sentence Alignment
- Multilingual Sentence Alignment
- Word Alignment
- Multilingual Word Alignment
- Linguistic Applications of Word Alignment
- Semantic Relatedness via Aligment Distributions
- Multilingual Translation Spotting
- Phraseme Identification
- Predicting Language Learners’ Transfer Errors
- Corpus Annotation
- Tokenization
- PoS Tagging & Lemmatization
- Interlingual Lemma Disambiguation ②
- Dependency Parsing
- Database Corpus
- Alignment Methods
- Text Alignment
- Sentence Alignment
- Multilingual Sentence Alignment
- Alignment Approach Based on Hierarchical Clustering ①
- Word Alignment
- Multilingual Word Alignment
- Linguistic Applications of Word Alignment
- Semantic Relatedness via Aligment Distributions
- Multilingual Translation Spotting
- Phraseme Identification ③
- Predicting Language Learners’ Transfer Errors
Definition
The term “alignment” denotes different concepts:
- A single correspondence = alignment unit
- A set of correspondences = alignment set
- The process of identifying corresponding elements
- The method of searching correspondences
It is applicable to parallel corpora (two languages)
or multiparallel corpora (more than two languages).
Alignment at Different Levels
- document or text alignment (larger units)
- sentence alignment
- word alignment (tokens)
- document or text alignment (larger units)
- sentence alignment
- sub-sentential alignment (multiple tokens)
- word alignment (tokens)
Alignment Unit
Correspondence of one or more structural elements (e.g., documents, articles, paragraphs, sentences, phrases, tokens) in at least two languages:
- Wir möchten nicht die Katze im Sack kaufen.
- Nous ne voulons pas acheter chat en poche.
Alignment units are sets of the elements in question:
{Katze, cat}Alignment Set
A list of alignment units of a given higher-level element:
- Wir möchten nicht die Katze im Sack kaufen.
- Nous ne voulons pas acheter chat en poche.
Alignment sets are sets of alignment units
(i.e., sets of sets of the elements in question):
| { | {Wir, Nous}, {kaufen, acheter}, {Katze, chat}, {im, en}, {nicht, ne, pas}, {Sack, poche}, {möchten, voulons} | } |
Hierarchical Alignment Set
A list of alignment units that constitute a hierachy:
- Wir möchten nicht die Katze im Sack kaufen.
- Nous ne voulons pas acheter chat en poche.
Hierarchical alignment units can only be proper subsets/supersets, but are not allowed to intersect: $A_1 \subset A_2 \vee A_1 \supset A_2 \vee A_1 \cap A_2 = \emptyset$
- {kaufen, acheter} $\subset$ {Katze, im, Sack, kaufen, acheter, chat, en, poche}
- {Katze, im, Sack, kaufen, acheter, chat, en, poche} $\supset$ {Katze, chat}
But Why?
Because of variation!
- Wir möchten nicht die Katze im Sack kaufen.
- Nous ne voulons pas acheter chat en poche.
- Não estamos interessados em comprar gato por lebre.
- We are not interested in buying a pig in a poke.
- Vi är inte intresserade av att köpa grisen i säcken.
Alignment of more than two languages (multilingual alignment) requires hierachical alignment sets.
Hierarchical Clustering Approach
for Multilingual Alignment
- Graph with
- nodes representing elements
- edges representing evidence for alignment
- Evidence comes from different (weighted) features.
- Weights are learned from manually aligned data.
Same approach for sentence and word alignment, but with different features and different linkage criteria
Features for Multilingual
Sentence Alignment
- Length-based
- Normalized sentence length (in characters)
- Positioning in the text with regard to lengths
- Lexical
- Multiword dictionaries
- Potential discourse markers
- Numbers
- Acronyms
- Alignment set from a bilingual sentence aligner
Gold Alignments
- 100 manually sentence-aligned documents
- Between 13 and 16 languages per text
- At two layers (hierarchical alignment units)
- Approximately 15 000 aligned sentences
- Using our own Hierarchical Alignment Tool (HAT)
Evaluation
- Cross-validation (5-fold) with feature weights optimized on training sets of 80 documents each
- Using the Metropolis algorithm on each training set to generate a Markov chain in the state spaces

- Using the Metropolis algorithm on each training set to generate a Markov chain in the state spaces
- Projection of multilingual to bilingual alignment sets
- Comparison with projected gold alignment sets
Results
- Average F-Score on training set ≈ 0.95
- Approximately 0.004 lower on test sets
- Comparable results for a bilingual aligner (hunalign)
Quality of multilingual sentence alignment similar to bilingual sentence alignment, but with two advantages:
- Aligned sentences in more than two languages
- Hierarchy allows for projection of smallest possible alignment units for any set of languages
Interlingual Lemma Disambiguation
- Lemmatization based on PoS tags is ambiguous. German participle “gehören” can be “hören” or “gehören”: Ich habe gehört, dass manche Landwirte ein an BSE erkranktes Rind lieber erschießen und vergraben, als den Fall zu melden.
- Comparison with aligned tokens in other languages can be used to disambiguate:
- English: I have heard that there are some farmers who, rather than report they have an animal with BSE, shoot that animal and bury it.
- Spanish: Tengo entendido que hay algunos ganaderos que, en lugar de informar de que tienen un animal con EEB, matan al animal y lo entierran.
- Swedish: Jag har hört att det är en del jordbrukare som i stället för att rapportera att de har ett djur med BSE, skjuter det djuret och begraver det.
Alignment Probability
Probability that a lemma $\lambda_s$ is aligned with lemma $\lambda_t$:
$p_a(\lambda_t|\lambda_s) = \frac{f_a(\lambda_s,\lambda_t)}{\sum_{\lambda_{t'}} f_a(\lambda_s,\lambda_{t'})}$
- Based on word alignment and lemmatization
- Includes ambiguous lemmas
Lemma with the highest alignment probability over
all languages replaces the ambiguous lemma:
$\lambda_s^{final} = \mathit{argmax}_{\lambda_s^i} \sum\limits_n p_a(\lambda_s^i|\lambda_t^n)$
Example
| gehören | hören | ||
| Dutch | horen | 0.2339 | 0.2909 |
| English | hear | 0.1515 | 0.3782 |
| Finnish | kuulla | 0.1143 | 0.3192 |
| French | entendre | 0.0694 | 0.1482 |
| Spanish | entender | 0.0043 | 0.0213 |
| Swedish | höra | 0.3314 | 0.2779 |
| $\sum p_a$ | 0.9047 | 1.4357 |
Phraseme Identification
- Phrasemes can in some cases be identified in parallel corpora by their disagreeing ‘functional’ parts.
- A prime example are support verb constructions:
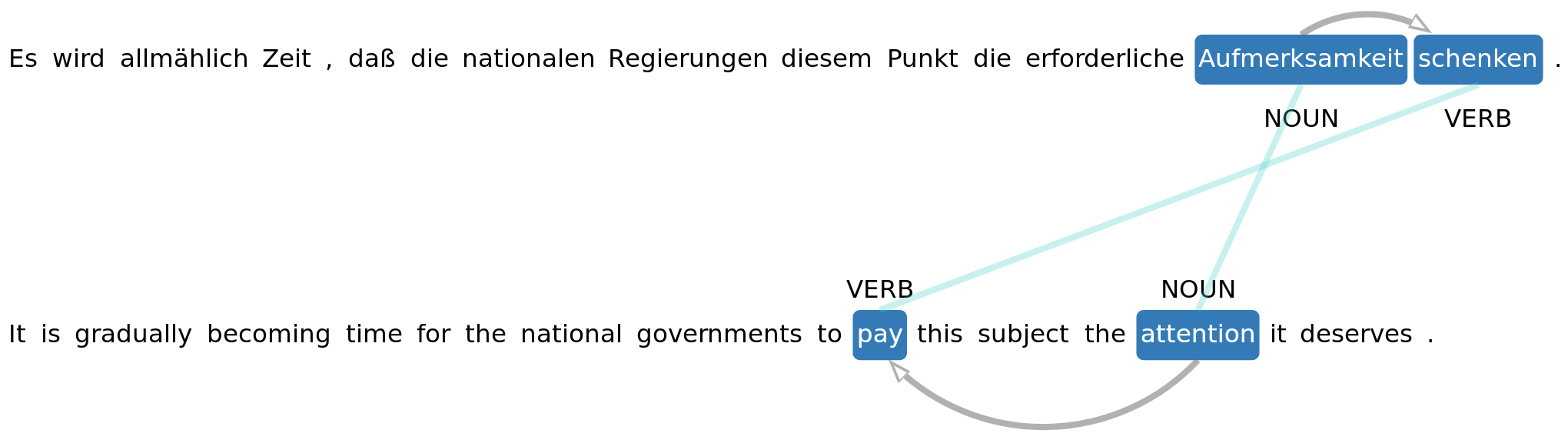
Approach
- Find constellations (tokens, token attributes and token relations) in a language pair such that:
- There is a direct object relation between
a verb and a noun in each language. - Both verbs and both nouns are aligned.
- There is a direct object relation between
- Calculate association measures on syntactic and alignment relations.
High values for the aligned nouns and low values
for the aligned verbs indicate idiomaticity.
Examples
| 1 | Gestalt annehmen | take shape | 39 |
| 2 | Präzedenzfall darstellen | set precedent | 10 |
| 3 | Armut bekämpfen | reduce poverty | 4 |
| 4 | Präzedenzfall schaffen | set precedent | 78 |
| 5 | Vorrang haben | take precedence | 47 |
| 6 | Illusion machen | have illusion | 10 |
| 7 | Hausaufgabe machen | do homework | 74 |
| 8 | Beileid aussprechen | send condolence | 2 |
| 9 | Vergleich ermöglichen | make comparison | 2 |
| 10 | Vergleich ziehen | make comparison | 2 |
| 11 | Vorschub leisten | give rise | 4 |
| 12 | Berücksichtigung finden | take account | 32 |
| 13 | Rekord halten | have record | 3 |
| 14 | Privileg genießen | have privilege | 4 |
| 15 | Beileid übermitteln | express condolence | 3 |
Interactive Exploration of
Association Measures
Our web application allows the user:
- to choose association measures for ordering
source and target language parts - to filter verbs and nouns
- to define a threshold
- to browse the respective examples
Conclusions
Alignment benefits
- corpus preparation
- (corpus) linguistics
- language learners
Multilingual hierarchical alignment
- provides for consistent alignment of many languages
- facilitates multilingual applications
- finds larger alignment units than bilingual alignment

Нашата работа, разбира се, не е приключила.

Doch unsere Arbeit ist selbstverständlich noch nicht beendet.

But our work of course is not finished.

Pero nuestra labor todavía no ha acabado.

Loomulikult ei ole meie töö sellega veel lõppenud.

Työmme ei ole luonnollisesti valmis.

Cependant, notre travail n’est bien entendu pas terminé.

Il nostro lavoro non è però concluso.

Maar ons werk zit er uiteraard nog niet op.

Nasza praca oczywiście nie dobiegła końca.

Todavia, o nosso trabalho ainda não terminou.

Dar munca noastră nu s-a terminat, desigur.

Naša práca sa však, samozrejme, neskončila.

Seveda pa naše delo ni končano.

Men allt arbete är naturligtvis inte avslutat.